
Connaissances et usages de l’IA générative chez les étudiants et les bib
Fin d’année dernière, j’ai été contacté par un enseignant de Paris-Saclay qui avait pour mission de produire un état des lieux sur les usages et les connaissances de la communauté universitaire de l’intelligence artificielle générative. Lui ayant dit tout ce que je savais sur le sujet (soit 2 vidéos Youtube), je pensais que l’histoire s’arrêterait là, mais les choses ont dérapé et je me suis retrouvé dans un amphi, lors de la Journée IA générative organisée par ce même enseignant, le 5 juin dernier, à raconter comment j’ai improvisé pendant huit mois sur l’IA générative (IAG) avant de commencer à l’intégrer dans mes formations. Voici le texte de mon intervention (expurgé et agrémenté).
Prudentes précisions contextualisées
Je suis bibliothécaire, physiquement basé à la BU Sceaux (droit, éco et gestion). Au sein de la DiBISO (Direction des Bibliothèques, de l’Information et de la Science Ouverte), j’occupe aussi la fonction de coordinateur des formations destinées aux étudiant.es de premier cycle, pour la DiBISO.
C’est dans ce contexte que j’ai été contacté, mais mon intervention se fonde exclusivement des observations menées à Sceaux, et pas sur tout le réseau.
Connaissances et usages observés chez les chez étudiants
Entre septembre 2023 et mai 2024, j’ai, à titre personnel, formé environ 250 étudiant.es :
40 étudiant.es en L1 éco-gestion
200 étudiant.es en L1-L2 Droit
15 étudiant.es en DU FLE
L’échantillon n’est pas représentatif et les méthodes d’enquêtes sont inexistantes. J’ai essentiellement discuté en cours avec les étudiants de manière informelle et pris des notes.
J’ai eu le privilège en outre d’interviewer deux tutrices documentaires en janvier (faut que je vous raconte d’ailleurs) dont une m’a dit des choses vraiment intéressantes sur la question.
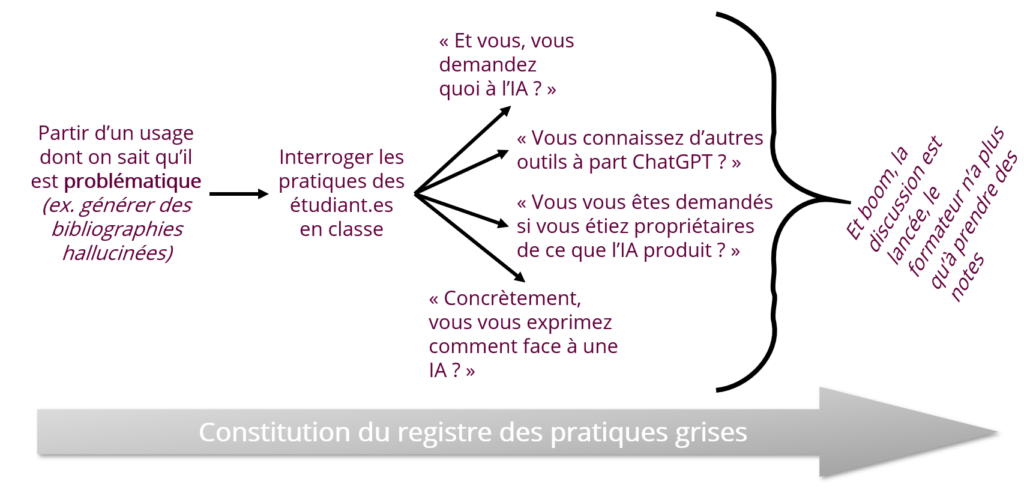
Les usages les plus problématiques (mais les plus simples à extirper du registre des pratiques)
Au fur et à mesure de que l’IA est entrée dans les pratiques et que nous avons cessé de lui demander des trucs un peu débiles pour nous moquer d’elle, nous avons commencé à la tester et à la questionner, sans vraiment comprendre comment elle fonctionnait. Et puisqu’en matière de recherche d’information, tout s’est plus ou moins googlisé, nous avons, je pense, tenté de transférer certaines de ces pratiques à des IAG comme ChatGPT. Ca a donné lieu à des usages complètement à côté de la plaque dont les professionnel.les de la recherche d’information que nous sommes se sont aussi rendu.es coupables. Par exemple :
- rechercher de l’actualité chaude (pas de blague dans les com’ s’il vous plaît) :
Très rarement rencontré parce qu’aisément falsifiable, des étudiant.es nous ont tout de même dit s’informer sur l’actualité via ChatGPT, courant novembre, ce qui était une gave erreur, jusqu’à l’arrivée de GPT-4o (omni) qui peut envoyer une requête dans un moteur de recherche à votre place.
- rechercher de l’information factuelle :
C’est un des premiers usages auquel nous avons été confrontés en service public, dès la fin de l’année universitaire 2022-2023 : au-delà de la simple actualité chaude, il est arrivé que des étudiant.es recherchent de l’information factuelle, sous la forme, par exemple, de bibliographies thématiques. Plus précisément, la pratique consistait à copier-coller un sujet d’exposé ou de mémoire en entrée et à demander des titres d’ouvrages en sortie. Ca a donné des épisodes assez grotesques où des étudiant.es, souvent en fin de Licence ou masterant.es, sont venu.es nous trouver avec des listes de 10, 15, 20 livres inexistants que nous avons gentiment vérifiés un à un.
C’est à ce moment-là que nous avons compris ce que signifiait « halluciner » pour une IA. J’ai observé ces usages jusqu’à la moitié du 1er semestre 2023-24 et puis, ils ont disparu de mon radar.
Ici, même remarque que plus haut : GPT-4o, Claude 3 Sonnet, Gemini, Copilot, Perplexity, toutes ces IAG « généralistes » prennent désormais « l’initiative »1 de composer une requête qu’elles envoient dans un moteur de recherche pour ensuite proposer une réponse à partir de la synthèse de quelques résultats2.
Malgré cela, je continue de considérer ces usages comme « problématiques » car ils ne sont pas fondés sur une familiarité minimale avec l’outil qui le propose. J’ai bien conscience qu’il est commercialement plus avantageux de centrer un certain nombre de services autour d’une seule marque, mais cela ne permet pas de distinguer un moteur de recherche d’une l’IAG et contribue fortement à un nouvel effet boîte noire.
Les usages gris
Les usages gris correspondent à des utilisations qui respectent les limites de ce que peuvent les LLM3, mais ils peuvent se révéler désastreux si mal maîtrisés. Or, c’est un point qui me manque dans mes observations : comment les étudiant.es s’expriment avec une IA générative de texte, autrement dit, comment ils rédigent leurs prompts.
- utiliser l’IAG comme agent conversationnel (il fallait y penser) :
Donc, utiliser l’IAG pour ce qu’elle est à la base : un agent conversationnel, tout simplement. C’est, dans mon expérience l’utilisation la plus courant de ChatGPT par les étudiant.es, avec une vraie augmentation à partir du semestre 2 chez les étudiant.es en Licence 2 de droit.
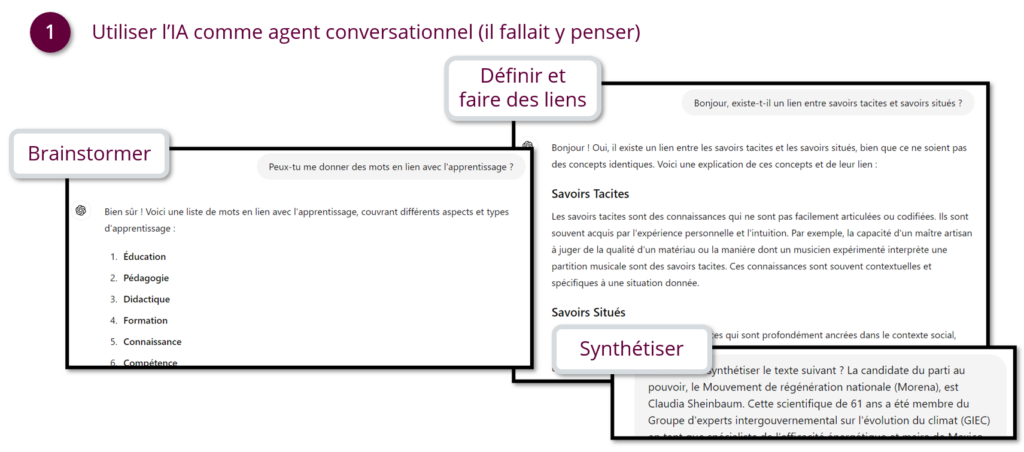
Pêle-mêle on peut citer : le brainstorming, la définition et la mise en relation de concepts, la reformulation de phrase (notamment pour adapter un propos original dans un registre plus soutenu), la synthèse…
En gros, tout ce qu’on arrive mieux à faire en discutant et en échangeant avec un autre être humain.
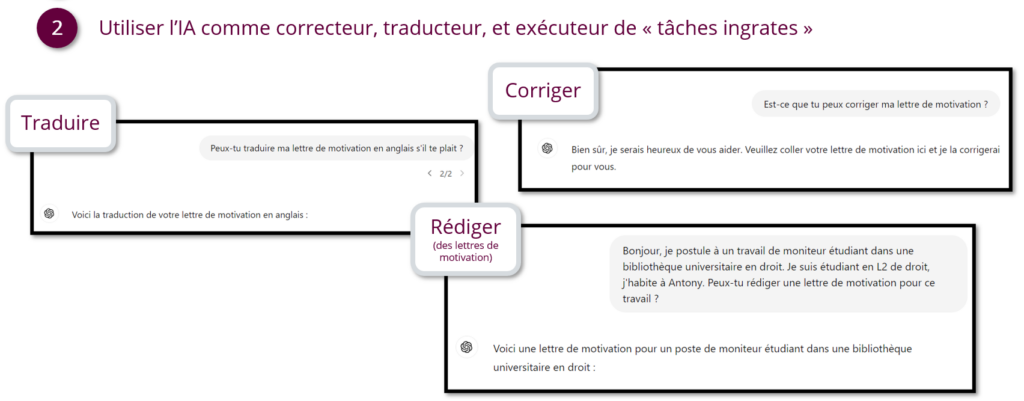
- utiliser l’IAG comme correctrice, relectrice, traductrice d’une production déjà existante
Dans un ordre d’idée plus pratico-pratique, des étudiant.es nous ont dit utiliser l’IA pour se faciliter la tâche dans des rédactions de CV et de lettres de motivation, traduction de termes (voire de lettres de motivation entières), etc.
Quelques étudiant.es, beaucoup plus rares (biais d’échantillonnage évident) nous ont dit utiliser l’IA pour corriger et optimiser du code.
Un autre regard, l’IA, béquille cognitive ?
Je le disais plus haut, j’ai pu interviewer deux tutrices documentaires (chargées d’accompagner les étudiant.es dans leurs recherches doc) dont une m’a spécifiquement rapporté ses observations quant à l’usage de l’IAG chez les étudiant.es, au moins pendant le premier semestre 2023-2024. Jugez plutôt :
« Donc moi j’ai des étudiants qui viennent et dès qu’ils veulent une réponse à une question, ou dès qu’ils veulent voir si le plan qu’ils proposent pour leur TD ça marche, c’est directement « on va sur ChatGPT », ou alors une définition, alors qu’ils ont accès à quand même plein de ressources. J’ai l’impression qu’il y a cette facilité de la part des étudiants de se rendre directement sur ChatGPT. Alors je sais pas si c’est pour combler un manque de confiance ou si c’est plus une question de fainéantise, mais je pense plutôt que c’est la question de la confiance.
Enfin j’ai l’impression qu’ils sortent d’une période Covid, ils ont passé le bac limite en distanciel et du coup j’ai l’impression qu’ils se rendent pas trop compte de ce que peut être la faculté, l’université et donc je pense que ça crée un manque de confiance. Et du coup ils comblent ce manque de confiance en allant sur ChatGPT, c’est surtout ça.
Moi aussi je suis là pour leur dire non, ce que tu fais c’est bien, ou voilà ce que tu fais, c’est pas bien, mais c’est pas une raison pour directement aller sur ChatGPT, voilà, on reprend tout et puis on recommence. […]
J’ai l’impression qu’ils vont d’abord sur ChatGPT, avant même que ça sorte de leur tête et une fois qu’ils ont ce qu’ils ont sur ChatGPT, c’est là qu’ils réfléchissent. Est-ce que c’est cohérent ? Est-ce que je garde ? Est-ce que j’enlève ? Si on utilise l’intelligence artificielle ça doit être l’inverse. D’abord on réfléchit, d’abord on se pose, on étudie les notions, les termes, et ensuite on peut affiner avec parce que voilà, ça c’est là.
C’est vrai que c’est pas mal, mais ils font ça à l’envers et je pense que c’est par manque de confiance, pour pas dire des bêtises, pour pas passer pour quelqu’un qui connaît pas son cours. »
Improviser pour s’adapter : parler de l’IAG et faire parler de l’IAG en classe
Je vous passe toute une brillante partie sur la façon dont le « monde des bibliothèques » a réagi à partir de décembre 2022, parce que vous savez déjà ce qu’il s’est passé, et que ça va encore me valoir des problèmes.
Partons sur mon expérience personnelle, donc.
Je suis parti d’usages problématiques plus ou moins répandus chez les étudiant.es, comme, par exemple la génération de listes d’ouvrages, qui donne à l’IA interrogée l’occasion d’halluciner un peu, l’idée étant de faire réagir l’audience avec quelques démos pour d’embrayer sur diverses questions qui, d’expérience ont plutôt intéressé les étudiants et lancé des discussions.
Ca a été l’occasion pour moi de prendre quelques notes et d’intégrer de nouvelles pratiques dans mon registre.
Pourquoi prendre ce temps plutôt que de me mettre à jour le plus rapidement possible sur la technologie ?
Parce que, pour être franc, le sujet ne me passionne pas, et je ne peux pas m’empêcher de considérer l’IAG, telle qu’elle se présente à nous aujourd’hui, comme un joujou très couteux et non nécessaire à notre mission de service public ;
Parce que, nous l’avons toutes et tous vécu, l’évolution de ces joujoux est allée extrêmement vite. J’ai bien commencé à regarder quelques vidéos de vulgarisation, et quelques tutos pour prompter comme un salcero, mais ma courbe de progression s’est toujours aplatie face aux avancées de ChatGPT, Bard puis Gemini et les autres ;
Parce que, par souci d’efficacité pédagogique j’ai voulu savoir sur quels types d’usages réels et observés mettre l’accent pour mieux en parler avec les étudiant.es et, éventuellement, les intégrer de manière plus systématique, ou en faire des cas d’usage à des fins d’analyse critique.
Fini l’impro, on passe aux choses sérieuses ?
Première tentative d’intégrer l’IAG dans un process de recherche documentaire
Dans le cadre d’un cours destiné à des étudiant.es en DU FLE, non francophones donc, j’ai, pour la première fois, intégré pleinement l’IA comme outil-étape dans une méthodologie de la recherche d’information.
Très grossièrement, l’idée est de se servir de l’IAG pour dégager des champs sémantiques4, après une analyse approfondie du sujet, de la consigne, du type de travail attendu et surtout du contexte de l’apprenant. Ce dernier reste généralement à l’état d’implicite et n’apparait pas souvent comme élément à prendre en compte dans une stratégie de recherche.
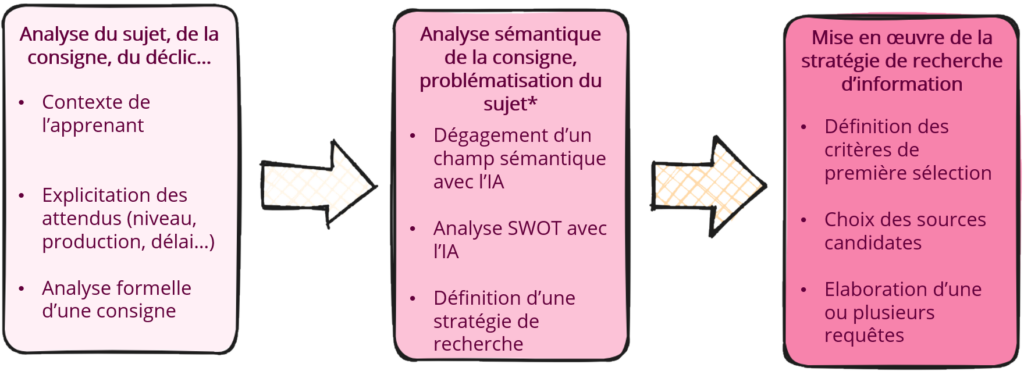
C’est ce travail de contextualisation qui, outre le fait qu’il est fondamental pour l’étudiant lui-même, va être à la base de la construction d’un prompt qui doit interroger l’IAG de manière efficace et reproductible (condition sine qua non pour intégrer cette étape dans une méthode).
La suite, c’est-à-dire la mise en œuvre de la stratégie et de la planification de la recherche, reste assez classique, telle que je l’ai élaborée pour le moment, il s’agit d’une sélection des principales sources et bases de données, et une explicitation des principaux critères de fiabilité et de pertinence attendus dans les informations recherchées. La définition d’un champ sémantique par une IAG peut s’accompagner d’une analyse SWOT pour dégager des liens de causalité entre plusieurs concepts.
C’est ce travail qui peut permettre de construire très rapidement des requêtes à visée exhaustive pour faire remonter toute l’information en un minimum de temps.
Plus concrètement, voilà ce que cela a donné pour les étudiants en DU FLE au mois de mai : il s’agit d’une petite partie du cours qui leur a été donné, la « recette » d’un prompt un peu plus efficace, avec au minimum quatre ingrédients :
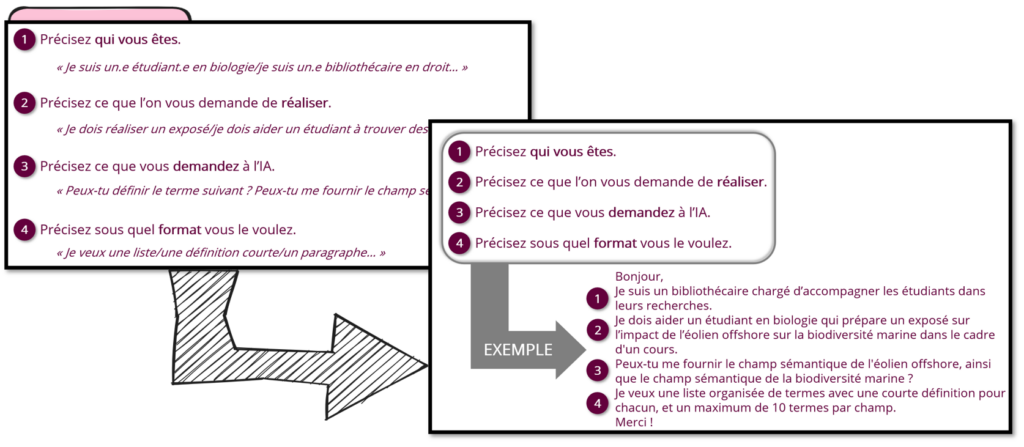
Le contexte de la personne, sa discipline, son niveau ;
L’attendu universitaire : le type de travail, la production, le livrable de l’humain, aussi précis que possible ;
La demande précise à l’IA, donc pas le sujet, pas la consigne, mais ce que l’on demande à la machine : un liste de termes, un champ sémantique, une analyse SWOT, ect. ;
Le format de sortie de l’IA, une liste, un paragraphe, du LateX, VBA, Python…
La distinction entre l’attendu universitaire, ou ce qui est demandé à l’apprenant et ce qui est demandé à l’IAG interrogée est cruciale : l’IAG est capable de d’associer un type de production comme un exposé ou un mémoire avec un niveau de langage et un niveau de précision qu’elle va pondérer avec le contexte de la personne ; ChatGPT ou Claude ne fourniront pas le même champ sémantique à un.e étudiant.e en France depuis 6 mois, à un.e bibliothécaire qui habite dans une BU spécialisée en droit, ou à un.e étudiant.e en L3 de biologie.
Cette distinction ouvre aussi la voie à des moyens pratiques d’explicitation des objectifs pédagogiques (comprenant par exemple la production formelle attendue) et des étapes pour y parvenir (en l’occurrence, dégager un champ sémantique).
Sans trop de surprise, le même prompt donné à ChatGPT, Claude, Gemini, ect., va donner exactement la même structure de réponse, ce qui va permettre de les comparer un peu plus efficacement.
Et les IA « académiques » on en pense quoi ?
Eh bien pas forcément grand chose, d’une part parce qu’il faut prendre le temps de les explorer, d’autre part parce qu’elles sont très souvent payantes.
Mais, la encore, grossièrement, je vois trois principales fonctions à ces outils
La cartographie de réseaux de publication, ou, en résumé, ce qui relève de la scientométrie.
L’extraction d’information d’une ou plusieurs ressources (textuelles, mais l’image commence à donner des résultats intéressants).
La synthèse d’une masse importante de papiers et la mise en forme d’une réponse courte.
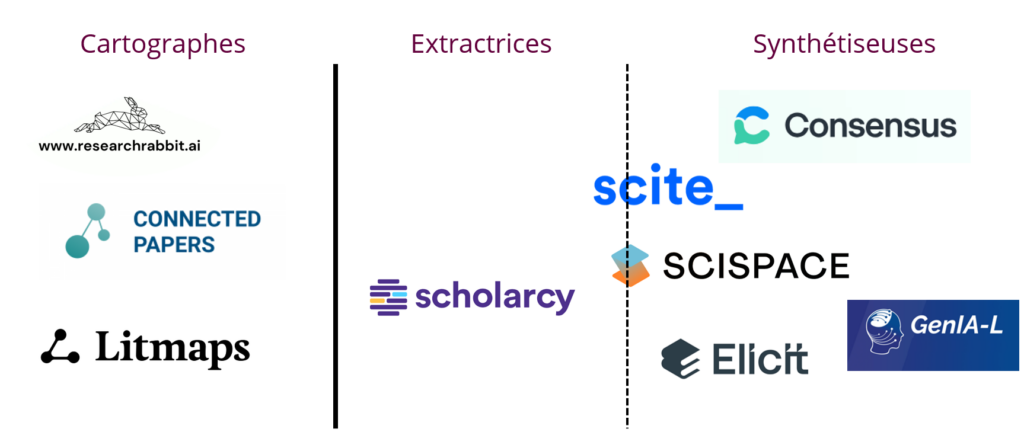
Je remarque qu’une bonne partie des outils propose à la fois les fonctions d’extraction et de synthèse.
Evidemment la qualité de ces outils dépend en bonne part de la qualité des bases de données sur lesquelles ils se fondent, mais, généralement, c’est plutôt qualitativement intéressant. En revanche, le traitement, la synthèse et la mise en forme me laissent un peu dubitatif, d’autant que je ne suis pas en mesure d’en juger de la qualité, pour ça on aurait besoin des retours des enseignants et des doctorants.
Les risques pour les bibliothécaires-formateur.ices
Le premier risque c’est donc de se perdre face à cette diversité d’outils qui évoluent, changent de nom, vont certainement disparaitre quand les modèles économiques vont se stabiliser et les quasi-monopoles se constituer. Nous n’avons pas le temps de tous les tester et de les évaluer, à moins d’y consacrer une part substantielle de notre fiche de poste, ce que nous n’avons pas toutes et tous le luxe de faire.
Nous risquons aussi de former à n’importe quoi n’importe comment et faire plus de mal que de bien dans cette course. Il ne serait pas sain de faire de nos formations et de nos enseignements méthodologiques des galeries de portraits
Enfin, nous risquons de nous faire les VRP low-cost de ces outils qui ne nous appartiennent pas, faute d’un recul suffisant sur nos pratiques. Les présenter superficiellement s’apparenterait à mon sens à de la publicité et, pire encore, à participerait orienter les utilisateurs vers les usages qui ont été pensés et voulus par les fournisseurs d’IAG qui n’ont pas forcément les mêmes objectifs que nous.
Alors faut-il céder aux sirènes de la course à l’IA générative pour tenter de s’assurer une place qui n’est de toute façon pas la nôtre puisque ne nous ne sommes pas rémunérés par les acteurs de l’IAG ? Peut-être. Vous faites ce que vous voulez.
Mais en attendant qu’OpenAI me contacte pour me proposer un juteux contrat, je préfère conserver un certain recul et n’intégrer l’IAG que de façon circonspecte dans mes formations.
A quelques nuances près.
Face aux risques
Une attitude purement attentiste ne serait pas saine face au défi de l’IAG. Entre l’intégration de simples usages dans des process déjà existants et les utilisations expertes des outils les plus spécialisés, il me semble que les bibliothèques, et la communauté universitaire dans son ensemble, peuvent se charger de l’émergence, autant chez les publics que chez nous, d’une véritable littératie info-documentaire, informatique et numérique. Ce que nous transmettons en classe, dans nos cours en ligne, en renseignement bibliographique, dans nos choix éditoriaux et même dans la manière dont nous investissons nos espaces, doit être chargé d’une importante portée critique réflexive et ne pas se réduire à de simples recettes techniques non éditorialisées.
Et pour cela, pas le choix il faut qu’on travaille sur notre compréhension profonde de l’IA, de l’IA générative, des LLM, du fonctionnement des transformers et du travail de pré-prompt accompli par les fournisseurs, nous devons aussi affiner nos connaissances des enjeux sociaux, éthiques, économiques et environnementaux, nous devons nous intéresser aux implications légales, notamment en termes de propriété intellectuelle, et j’en passe…
C’est absolument gigantesque, mais il s’agit, ce me semble, du strict nécessaire pour pour s’engager sur des voies plus ambitieuses que ce que j’ai proposé plus haut (et encore).
- Initiative déclenchée, semble-t-il, par des genres de safe words comme « aujourd’hui », « actuellement », « existant », etc. ↩︎
- Il est important de noter que ces IAG ne sont pas « banchées » sur le web comme on a tendance à le dire, en revanche, elles intègrent des moteurs de recherches (développés spécifiquement pour elles, notamment dans le cas de ChatGPT). ↩︎
- Large language modele : réseaux de neurones sur lesquels sont fondés une grande partie de nos IAG actuelles. ↩︎
- Sur la recommandation de Christophe Poupet, directeur des ateliers Canopé de Bourges et de Chateauroux et ancien professeur-documentaliste, lors d’une intervention à la Journée d’étude pour les professionnels de la documentation et des bibliothèques de BibDoc 37, le 11 avril 2024. ↩︎